Machine learning gây nên cơn sốt công nghệ trên toàn thế giới trong vài năm nay. Trong giới học thuật, mỗi năm có hàng ngàn bài báo khoa học về đề tài này. Trong giới công nghiệp, từ các công ty lớn như Google, Facebook, Microsoft đến các công ty khởi nghiệp đều đầu tư vào machine learning. Hàng loạt các ứng dụng sử dụng machine learning ra đời trên mọi linh vực của cuộc sống, từ khoa học máy tính đến những ngành ít liên quan hơn như vật lý, hóa học, y học, chính trị. AlphaGo, cỗ máy đánh cờ vây với khả năng tính toán trong một không gian có số lượng phần tử còn nhiều hơn số lượng hạt trong vũ trụ, tối ưu hơn bất kì đại kì thủ nào, là một trong rất nhiều ví dụ hùng hồn cho sự vượt trội của machine learning so với các phương pháp cổ điển.
Đang xem: Machine learning là gì
Vậy thực chất, machine learning là gì?
Để giới thiệu về machine learning, mình xin dựa vào mối quan hệ của nó với ba khái niệm sau:1. Machine learning và trí tuệ nhân tạo (Artificial Intelligence hay AI)2. Machine learning và Big Data.3. Machine learning và dự đoán tương lai.
Trí tuệ nhân tạo, AI, một cụm từ vừa gần gũi vừa xa lạ đối với chúng ta. Gần gũi bởi vì thế giới đang phát sốt với những công nghệ được dán nhãn AI. Xa lạ bởi vì một AI thực thụ vẫn còn nằm ngoài tầm với của chúng ta. Nói đến AI, hẳn mỗi người sẽ liên tưởng đến một hình ảnh khác nhau. Vài thập niên gần đây có một sự thay đổi về diện mạo của AI trong các bộ phim quốc tế. Trước đây, các nhà sản xuất phim thường xuyên đưa hình ảnh robot vào phim (như Terminator), nhằm gieo vào đầu người xem suy nghĩ rằng trí tuệ nhân tạo là một phương thức nhân bản con người bằng máy móc. Tuy nhiên, trong những bộ phim gần hơn về đề tài này, ví dụ như Transcendence do Johny Depp vào vai chính, ta không thấy hình ảnh của một con robot nào cả. Thay vào đó là một bộ não điện toán khổng lồ chỉ huy hàng vạn con Nanobot, được gọi là Singularity. Tất nhiên cả hai hình ảnh đều là hư cấu và giả tưởng, nhưng sự thay đổi như vậy cũng một phần nào phản ánh sự thay đổi ý niệm của con người về AI. AI bây giờ được xem như vô hình vô dạng, hay nói cách khác có thể mang bất cứ hình dạng nào. Vì nói về AI là nói về một bộ não, chứ không phải nói về một cơ thể, là software chứ không phải là hardware.
Xem thêm: Bảng Ngọc Xeniel, Cách Chơi Xeniel Liên Quân Mùa 16, Hướng Dẫn Chơi Xeniel Liên Quân Mobile Mùa 18
Trong giới hàn lâm, theo hiểu biết chung, AI là một ngành khoa học được sinh ra với mục đích làm cho máy tính có được trí thông minh. Mục tiêu này vẫn khá mơ hồ vì không phải ai cũng đồng ý với một định nghĩa thống nhất về trí thông minh. Các nhà khoa học phải định nghĩa một số mục tiêu cụ thể hơn, một trong số đó là việc làm cho máy tính lừa được Turing Test. Turing Test được tạo ra bởi Alan Turing (1912-1954), người được xem là cha đẻ của ngành khoa học máy tính hiện đại, nhằm phân biệt xem người đối diện có phải là người hay không (xem phim The Imitation Game để biết thêm về Alan Turing).
AI thể hiện một mục tiêu của con người. Machine learning là một phương tiện được kỳ vọng sẽ giúp con người đạt được mục tiêu đó. Và thực tế thì machine learning đã mang nhân loại đi rất xa trên quãng đường chinh phục AI. Nhưng vẫn còn một quãng đường xa hơn rất nhiều cần phải đi. Machine learning và AI có mối quan hệ chặt chẽ với nhau nhưng không hẳn là trùng khớp vì một bên là mục tiêu (AI), một bên là phương tiện (machine learning). Chinh phục AI mặc dù vẫn là mục đích tối thượng của machine learning, nhưng hiện tại machine learning tập trung vào những mục tiêu ngắn hạn hơn như:
Làm cho máy tính có những khả năng nhận thức cơ bản của con người như nghe, nhìn, hiểu được ngôn ngữ, giải toán, lập trình, …
Hỗ trợ con người trong việc xử lý một khối lượng thông tin khổng lồ mà chúng ta phải đối mặt hàng ngày, hay còn gọi là Big Data.
Big Data thực chất không phải là một ngành khoa học chính thống. Đó là một cụm từ dân gian và được giới truyền thông tung hô để ám chỉ thời kì bùng nổ của dữ liệu hiện nay. Nó cũng không khác gì với những cụm từ như “cách mạng công nghiệp”, “kỉ nguyên phần mềm”. Big Data là một hệ quả tất yếu của việc mạng Internet ngày càng có nhiều kết nối. Với sự ra đời của các mạng xã hội nhưng Facebook, Instagram, Twitter, nhu cầu chia sẻ thông của con người tăng trưởng một cách chóng mặt. Youtube cũng có thể được xem là một mạng xã hội, nơi mọi người chia sẻ video và comment về nội dung của video. Để hiểu được quy mô của Big Data, hãy xem qua những con số sau đây (tính đến thời điểm bài viết):
Và những con số này đang tăng lên theo từng giây!
Bùng nổ thông tin không phải là lý do duy nhất dẫn đến sự ra đời của cụm từ Big Data. Nên nhớ rằng Big Data xuất hiện mới từ vài năm gần đây nhưng khối lượng dữ liệu tích tụ kể từ khi mạng Internet xuất hiện vào cuối thế kỉ trước cũng không phải là nhỏ. Thế nhưng, lúc ấy con người ngồi quanh một đống dữ liệu và không biết làm gì với chúng ngoài lưu trữ và sao chép. Cho đến một ngày, các nhà khoa học nhận ra rằng trong đống dữ liệu ấy thực ra chứa một khối lượng tri thức khổng lồ. Những tri thức ấy có thể giúp cho ta hiểu thêm về con người và xã hội. Từ danh sách bộ phim yêu thích của một cá nhân chúng ta có thể rút ra được sở thích của người đó và giới thiệu những bộ phim người ấy chưa từng xem, nhưng phù hợp với sở thích. Từ danh sách tìm kiếm của cộng đồng mạng chúng ta sẽ biết được vấn đề nóng hổi nhất đang được quan tâm và sẽ tập trung đăng tải nhiều tin tức hơn về vấn đề đó. Big Data chỉ thực sự bắt đầu từ khi chúng ta hiểu được gía trị của thông tin ẩn chứa trong dữ liệu, và có đủ tài nguyên cũng như công nghệ để có thể khai thác chúng trên quy mô khổng lồ. Và không có gì ngạc nhiên khi machine learning chính là thành phần mấu chốt của công nghệ đó. Ở đây ta có một quan hệ hỗ tương giữa machine Learning và Big Data: machine learning phát triển hơn nhờ sự gia tăng của khối lượng dữ liệu của Big Data; ngược lại, gía trị của Big Data phụ thuộc vào khả năng khai thác tri thức từ dữ liệu của machine learning.
Xem thêm: Ib Game Là Gì ? Cách Dùng Ib Trên Facebook Cách Dùng Ib Trên Facebook
Ngược dòng lịch sử, machine learning đã xuất hiện từ rất lâu trước khi mạng Internet ra đời. Một trong những thuật toán machine learning đầu tiên là thuật toán perceptron được phát minh ra bởi Frank Rosenblatt vào năm 1957. Đây là một thuật toán kinh điển dùng để phân loại hai khái niệm. Một ví dụ đơn gỉan là phân loại thư rác (tam gíac) và thư bình thường (vuông). Chắc các bạn sẽ khó hình dung ra được làm thế nào để làm được điều đó. Đối với perceptron, điều này không khác gì với việc vẽ một đường thẳng trên mặt phẳng để phân chia hai tập điểm:
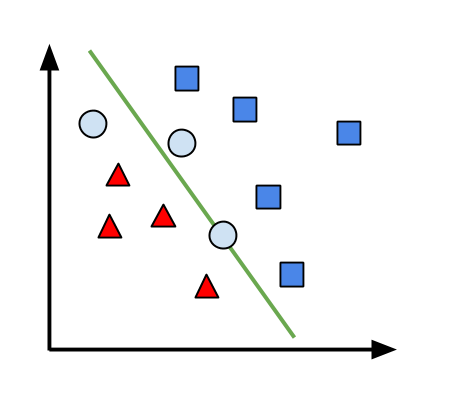
Những điểm tam giác và vuông đại diện cho những email chúng ta đã biết nhãn trước. Chúng được dùng để “huấn luyện” (train) perceptron. Sau khi vẽ đường thẳng chia hai tập điểm, ta nhận thêm các điểm chưa được dán nhãn, đại diện cho các email cần được phân loại (điểm tròn). Ta dán nhãn của một điểm theo nhãn của các điểm cùng nửa mặt phẳng với điểm đó.
Sơ lược quy trình phân loại thư được mô tả sau. Trước hết, ta cần một thuật toán để chuyển email thành những điểm dữ liệu. Công đoạn này rất rất quan trọng vì nếu chúng ta chọn được biểu diễn phù hợp, công việc của perceptron sẽ nhẹ nhàng hơn rất nhiều. Tiếp theo, perceptron sẽ đọc tọa độ của từng điểm và sử dụng thông tin này để cập nhật tham số của đường thẳng cần tìm. Các bạn có thể xem qua demo của perceptron (điểm xanh lá cây là điểm perceptron đang xử lý)


